Fallbacks and retries
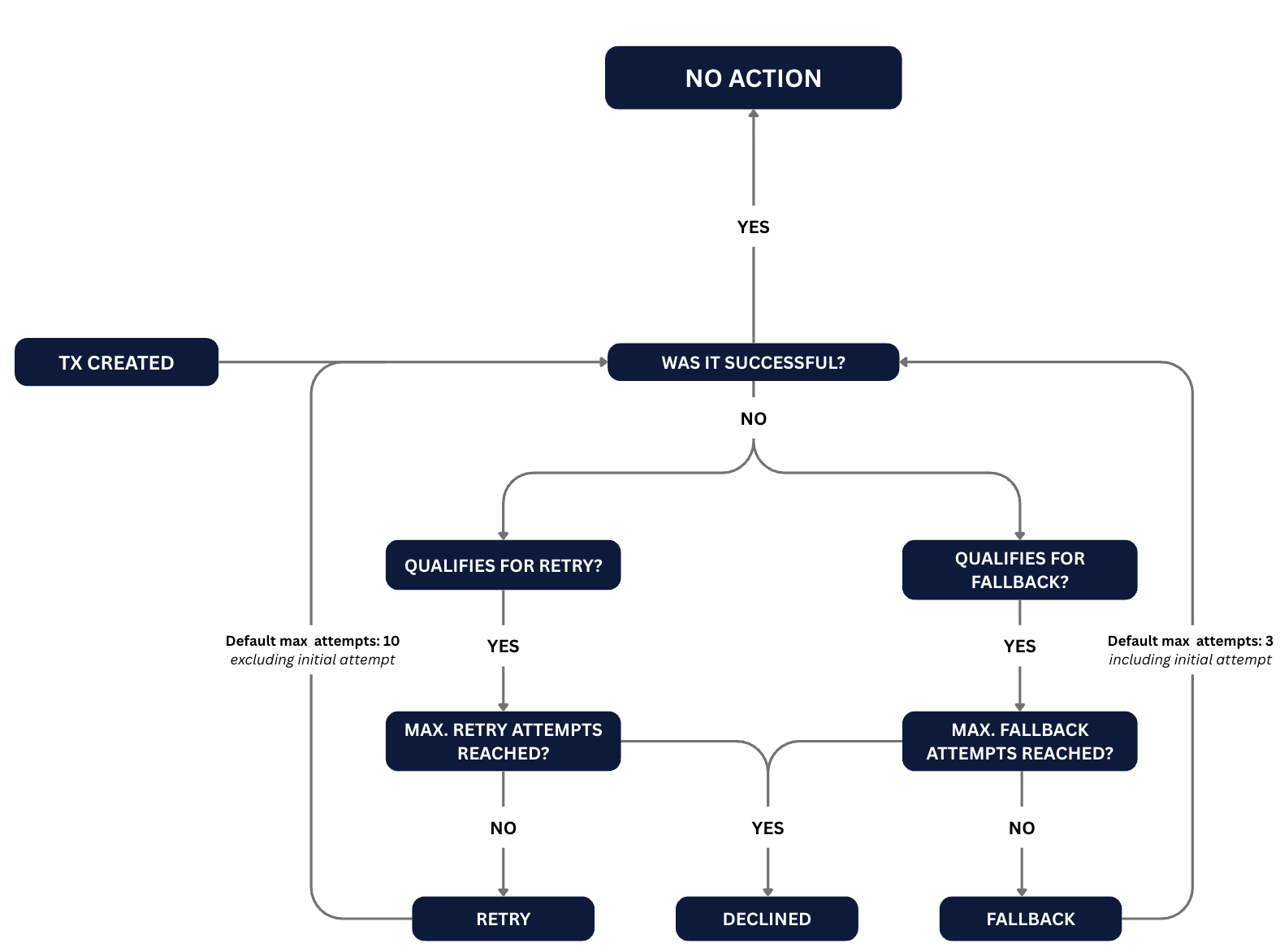
Requests can fail. Whether due to network issues, downstream service failures, timeouts, or other errors. A robust integration should always account for such failures by implementing fallbacks and retry mechanisms to ensure reliability and maintain continuity of service.
Fallbacks
A fallback is the ability to automatically switch to an alternative provider or route when the primary one is unavailable or fails during a transaction flow.
Typical fallback scenarios include:
- Authentication fallback: If a 3DS authentication fails or times out, route the transaction through another 3DS provider.
- Authorization fallback: If an issuer or acquirer is temporarily unreachable, switch to a backup acquirer if supported.
- Scheme routing fallback: In case of a scheme-specific failure (e.g. Visa or Mastercard), re-route to another eligible scheme for co-branded cards (when regulation allows).
Retries
A retry is the process of automatically repeating a failed request when the failure is likely temporary (e.g. timeouts, 5xx responses). It is repeating the initial request with the same conditions.
Key retry guidelines:
- Increasing wait times between retries to reduce load on the service and improve success chances.
- Limited retry attempts to avoid long transaction times or duplicate operations.
- Only retry idempotent operations, such as authentication or tokenization steps — not charge or capture unless designed to handle duplicates.
- Log all retries and expose them for observability and audit purposes.
Retries improve resilience but must be controlled to avoid side effects in payment flows.
Updated 8 months ago